
IBM SPSS Statistics中的個案添加功能,適合用于同一系列變量下的不同個案數(shù)據(jù)的合并。比如,小組成員需要分別收集女性與男性的樣本數(shù)據(jù),在匯總的時候,就需要通過個案添加合并的功能,整合女性與男性的數(shù)據(jù)。
接下來,就讓我們使用一個實際例子演示一下個案添加合并的操作方法。
一、打開需合并的數(shù)據(jù)
首先,如圖1所示,打開需要合并的兩個數(shù)據(jù)文件。
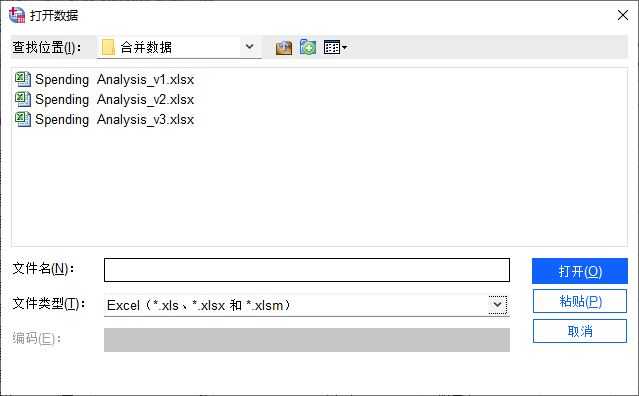
圖1:打開數(shù)據(jù)
如圖2所示,可以看到,數(shù)據(jù)集5中缺少了一些個案數(shù)據(jù),另外兩個數(shù)據(jù)文件中的“地區(qū)”變量命名不一致。

圖2:比較數(shù)據(jù)的差異
二、使用添加個案的合并數(shù)據(jù)功能
接著,就可以打開SPSS的添加個案數(shù)據(jù)合并功能,將兩個數(shù)據(jù)集的數(shù)據(jù)合并起來。需要注意的是,我們要在數(shù)據(jù)集5(即缺少數(shù)據(jù)的文件)中使用數(shù)據(jù)合并功能。

圖3:合并之添加個案功能
接著,如圖4所示,指定已打開的數(shù)據(jù)集4為合并數(shù)據(jù)集。

圖4:指定合并的數(shù)據(jù)文件
然后,到了比較重要的步驟,我們需要對合并后的數(shù)據(jù)變量進(jìn)行設(shè)置。如圖5所示,變量括號中含*號的表示活動數(shù)據(jù)集(即數(shù)據(jù)集5)包含的變量,而括號中含+號的表示數(shù)據(jù)集4包含的變量。另外,其中提及的變量含義如下:
1.非成對變量,即兩個數(shù)據(jù)表中存在差異的變量
2.新的活動數(shù)據(jù)集中的變量,即兩個數(shù)據(jù)文件共同包含的變量,合并數(shù)據(jù)后會將其保留
3.指定個案源變量,可選的新變量,用于指示個案的來源
如圖5所示,可以看到,合并后的數(shù)據(jù)會保留賬號、性別、客單價與點擊頁面數(shù)四個變量。
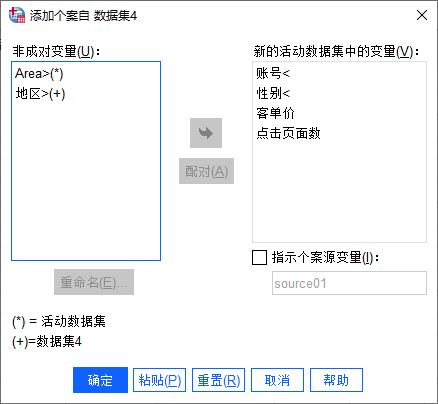
圖5:設(shè)置包含的變量
對于非成對變量,由于Area與地區(qū)實際上是同一變量,我們可以將其配對。如圖6所示,同時選中Area與地區(qū)變量(使用Ctrl鍵),然后,單擊“配對”按鈕。
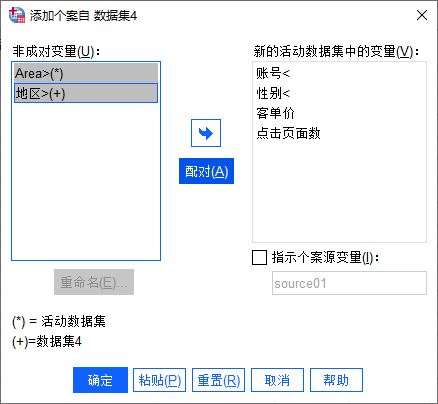
圖6:配對變量
如圖7所示,Area與地區(qū)變量將會在新的數(shù)據(jù)集中合并為同一變量。

圖7:完成變量的配對
最后,勾選“指定個案源變量”選項,方便后續(xù)分辨合并數(shù)據(jù)的來源。完成以上步驟后,即可單擊“確定”按鈕,正式合并數(shù)據(jù)。
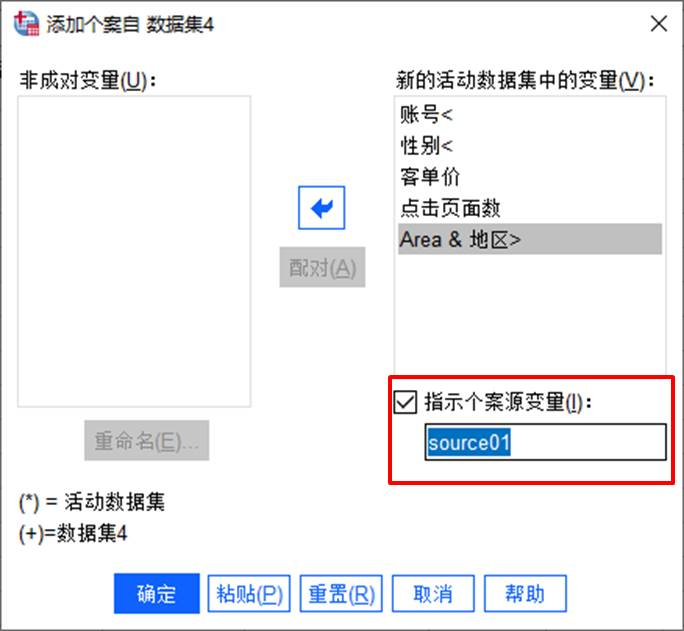
圖8:可導(dǎo)出的數(shù)據(jù)格式
完成了數(shù)據(jù)的合并后,如圖9所示,可以看到數(shù)據(jù)集4(source01標(biāo)注為1)來源的數(shù)據(jù)導(dǎo)入到數(shù)據(jù)集5的數(shù)據(jù)后面。
由于合并功能只是將兩個數(shù)據(jù)集的數(shù)據(jù)匹配變量合并,無篩選重復(fù)項功能,因此更適用于無重復(fù)項的數(shù)據(jù)集合并。

圖9:完成個案的添加
以上就是SPSS數(shù)據(jù)合并中的個案添加合并的方法介紹,該功能適用于需要合并個案數(shù)據(jù)的情況。








